Document Splitter
Efficiently split documents into manageable pieces for further processing.
What is Document Splitter?
The Document Splitter allows you to break down large documents into smaller, manageable chunks. This is particularly useful for text analysis, machine learning tasks, and other scenarios where handling large texts in smaller parts is more efficient.
How to use it?
The Document Splitter can be used to split documents using various splitting methods. It provides flexibility in choosing the type of splitter that best suits your document type and processing needs.
-
Configure Document Splitter:
-
Add the Document Splitter to your workflow.
-
Select the type of splitter from the dropdown list:
- Recursive Character Splitter:
The RecursiveCharacterTextSplitter takes a large text and splits it based on a specified chunk size. It does this by using a set of characters. The default characters provided to it are ["\n\n", "\n", " ", ""].
It takes in the large text then tries to split it by the first character
\n\n. If the first split by \n\n is still large then it moves to the next character which is \n and tries to split by it. If it is still larger than our specified chunk size it moves to the next character in the set until we get a split that is less than our specified chunk size. - HTML Splitter: The HTML splitter processes a large HTML document by dividing it into smaller chunks, each up to 60 characters long. It does this by leveraging the HTML structure, initially splitting at natural tag boundaries. If a segment between tags exceeds the chunk size, it further divides the content within those tags. This recursive process continues until all segments are within the desired length. The splitter ensures no overlap between chunks, preserving the integrity and readability of the HTML content while making it more manageable.
- Markdown Splitter: The Markdown splitter processes a large Markdown document by dividing it into smaller chunks, each up to 60 characters long. It uses the Markdown structure, splitting at logical points such as headings, paragraphs, and code blocks. If a segment between these points exceeds the chunk size, it further divides the content within those segments. This recursive process continues until all segments are within the desired length. The splitter ensures no overlap between chunks, preserving the integrity and readability of the Markdown content while making it more manageable.
- Code Splitter: The JavaScript code splitter processes a large JavaScript code block by dividing it into smaller chunks, each up to 60 characters long. It leverages the JavaScript syntax, initially splitting at logical boundaries such as function declarations and comments. If a segment between these boundaries exceeds the chunk size, it further divides the content within those segments. This recursive process continues until all segments are within the desired length. The splitter ensures no overlap between chunks, maintaining the code's logical structure and readability while making it more manageable.
- Token Splitter: The TokenTextSplitter divides a large text into smaller chunks, each containing up to 10 tokens. This ensures that the text is split in a way that aligns with the token limits of language models, preventing token overflow. By using the TokenTextSplitter directly, each chunk is guaranteed to be within the specified token limit, making it suitable for handling texts that need precise token-based segmentation. This method is particularly useful for languages with complex tokenization, ensuring that each chunk is well-formed and adheres to the tokenizer's rules.
- Character Splitter:
The Character Splitter divides a large text into smaller chunks based on characters, with the separator being
\n\n. The chunk size is measured by the number of characters, allowing for precise control over the length of each segment. The splitter is configured with a chunk size of 1000 characters and an overlap of 200 characters. This method ensures that the text is split at logical points, preserving readability and context. The Character Splitter is simple and effective for handling long documents by creating manageable, character-based segments.
- Recursive Character Splitter:
The RecursiveCharacterTextSplitter takes a large text and splits it based on a specified chunk size. It does this by using a set of characters. The default characters provided to it are ["\n\n", "\n", " ", ""].
It takes in the large text then tries to split it by the first character
-
Example of usage
The Document Splitter can be effectively used in combination with other nodes such as a Vector Store and an Embedder to create a workflow that processes and stores document embeddings for efficient retrieval and analysis.
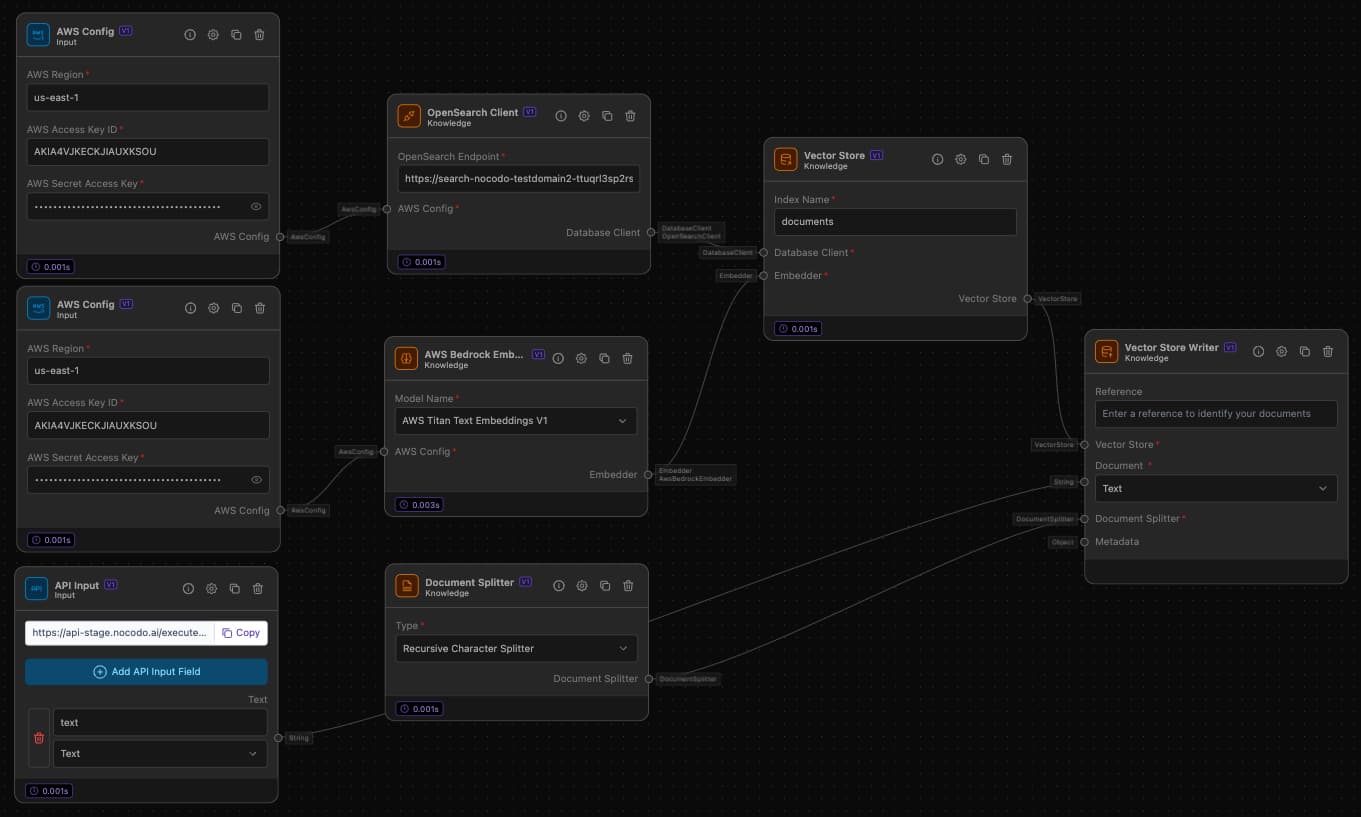
Example Task: Creating a Vector Store of Document Embeddings
Objective: Split a document, create embeddings, and store them in a vector store for efficient search and retrieval.
Step-by-Step Setup
-
AWS Configuration:
- Component: AWS Config
- Details: Enter AWS Region, Access Key ID, and Secret Access Key.
-
API Input:
- Component: API Input
- Details: Select 'AWS S3' as the storage provider, enter the file path and bucket name, and connect to AWS Config.
-
Split Document:
- Component: Document Splitter
- Details: Select the splitting strategy (e.g., 'Recursive Character Splitter').
- Connection: Connect Api Input to Document Splitter.
-
Embed Document Chunks:
- Component: AWS Bedrock Embedder
- Connection: Connect AWS Bedrock Embedder with AWS Config.
-
Setup OpenSearch Client:
- Component: OpenSearch Client
- Details: Enter the OpenSearch endpoint.
- Connection: Connect AWS Config to OpenSearch Client.
-
Vector Store:
- Component: Vector Store
- Details: Enter the index name (you can use the default 'documents').
- Connection: Connect Vector Store to OpenSearch Client and AWS Bedrock Embedder.
-
Store Embeddings in OpenSearch:
- Component: Vector Store Writer
- Details: Configrue the type of Document (
Text). - Connection: Connect Vector Store to Vector Store Writer, Document Splitter to Vector Store Writer and the API Input to the Vector Store Writer.
With this you are able to store all your documents via an API Upload into an OpenSearch Vector Store and you will be able to retrieve them with an Vector Store Reader and use them e.g. as a basis for a Chat Client