AWS Bedrock LLM
Harness the power of AWS Bedrock models to perform advanced language tasks.
What is the AWS Bedrock LLM?
The AWS Bedrock LLM allows you to execute language tasks using AWS Bedrock models such as the Claude or Amazon Titan Models. This node is configurable for model-specific settings such as temperature and top token probability, and optionally processes images for certain models. The results from the engaged language model are outputted for further use in your workflow.
How to use it?
-
Add AWS Bedrock LLM:
- Drag and drop the AWS Bedrock LLM into your workflow canvas.
-
Configure Input Parameters:
- Model Name: Select a model from the provided options (e.g., Claude Instant 1.2, Claude 2.0, Amazon Titan Text Express).
- Temperature: Set the model temperature to control the randomness of the output. A higher value makes the output more random.
- Top P: Set the top token probability to control the diversity of the output. A lower value makes the output more focused.
-
Connect Input Anchors:
- Prompt Text: Connect a node that provides the text prompt (e.g., a Text Input node).
- Image (Optional): If using models that support image processing, connect a File Input node that will provide the image.
-
Connect Output Anchors:
- Output Text: Connect this anchor to nodes that will process or display the output text (e.g., String Output node).
Antrophic Models
- Claude Instant 1.2: is a small, fast, and cost-effective model, a predecessor to Claude Haiku. While it provides quick and responsive performance, it is considered a legacy model with reduced coverage, understanding, and skill compared to Claude 3 models. It supports multilingual output without vision capabilities, has a 100K context window, and can output up to 4,096 tokens, ideal for quick tasks with lower complexity.
- Claude 2.0: is the predecessor to the Claude 3 series, offering strong all-around performance for its time. It is a legacy model with multilingual support but has limited coverage and skill compared to newer models. This model also lacks vision capabilities and has a 100K context window with a max output of 4,096 tokens, making it suitable for less demanding tasks.
- Claude 2.1: is an updated version of Claude 2 with improved accuracy but less coverage, understanding, and skill compared to Claude 3 models. It supports multilingual capabilities, though less effectively than its successors, and does not include vision support. It has a context window of 200K tokens and a maximum output of 4,096 tokens, suitable for applications needing a balance of performance and cost-efficiency.
- Claude 3 Sonnet: balances intelligence and speed, making it suitable for scaled deployments. It offers strong utility across various tasks with a focus on maintaining a balance between performance and efficiency. This model also supports multilingual and vision features, has fast latency, a 200K context window, and a max output of 4,096 tokens.
- Claude 3 Haiku: is the fastest and most compact model in the Claude 3 series, designed for near-instant responsiveness and quick, accurate performance. It is ideal for applications requiring rapid output and targeted results. This model supports multilingual and vision features, has the fastest latency, a 200K context window, and a max output of 4,096 tokens.
- Claude 3.5 Sonnet: is the most intelligent model in the Claude 3 series, offering the highest level of intelligence and capability for complex tasks. It supports multilingual and vision features, has a fast latency with a 200K context window, and can produce up to 8,192 tokens per output. It is ideal for scenarios requiring top-tier performance and deep understanding.
AWS Models
- Amazon Titan Text Express: is a versatile large language model optimized for English and multilingual support, capable of performing various tasks including open-ended text generation, conversational chat, retrieval augmented generation, code generation, and summarization.
- Amazon Titan Text Lite: is a lightweight, efficient model optimized for fine-tuning English-language tasks, suitable for use cases like summarization and copywriting where a smaller, cost-effective, and customizable model is preferred.
- Amazon Titan Text Premier: is a comprehensive large language model for text generation, designed for a variety of tasks including open-ended text generation, context-based question answering, code generation, and summarization, with integration into Amazon Bedrock Knowledge Base and Agents, and support for custom fine-tuning.
Meta Models
- Llama 3 8B Instruct: is a multilingual large language model with 8 billion parameters, optimized for multilingual dialogue and text generation. It supports text and code outputs in several languages, including English, German, French, and more, and is suitable for assistant-like chat and natural language tasks.
- Llama 3 70B Instruct: is a more advanced variant with 70 billion parameters, designed for complex multilingual dialogue and text generation. It supports multiple languages and is ideal for high-performance commercial and research applications requiring extensive knowledge and scalability.
Required AWS IAM Roles and Permissions
To use the AWS Bedrock LLM, you need to have the following IAM permissions assigned to the AWS credentials provided:
bedrock:InvokeModel: Permission to invoke AWS Bedrock models.s3:GetObject: Permission to fetch images from S3, if using image input.s3:PutObject: Permission to save outputs to S3, if necessary.
Ensure that your AWS credentials have the appropriate permissions to interact with the Bedrock service and any other AWS services like S3 for image processing.
Example of Usage
Example Task: AWS Bedrock LLM with Image Input
Objective: Create a API that creates alt titles for your images
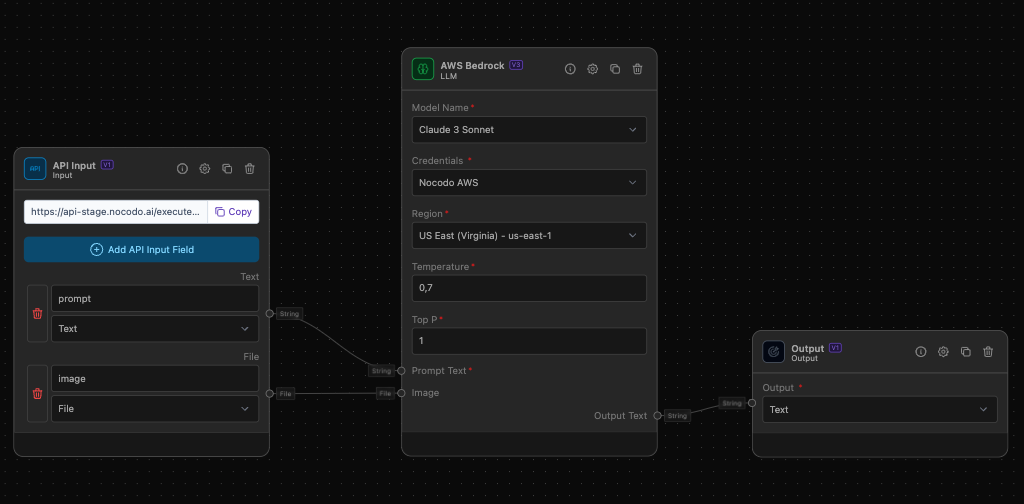
Step-by-Step Setup
-
- Use the API Input node to receive JSON data from an external API.
- Configure the API Input node to capture the incoming data.
- Add a variable called 'prompt'
-
AWS Bedrock LLM
- Model Name: Select 'Claude 3 Haiku'.
- Temperature: Set to 0.7.
- Top P: Set to 1.0.
- Outputs: Connect the 'Output Text' to a String Output node.
- Inputs:
- Connect the 'prompt' to the 'Prompt Text' Input of AWS Bedrock
- Connect the 'image' to the 'Image' Input of AWS Bedrock
-
String Output
- Configuration: Set the output type to 'Text' and connect it to display the generated ideas.
-
Call the API
- Call the API with a POST call and a body formated as 'form-data'
- You can use the following text for the prompt, but feel free to adapt it to your needs:
Please create a descriptive alt text for the image, only respnde with the alt text, describe only what you can see on the image, do not add additional details
Additional Information
- Temperature and Top P Settings: These parameters are crucial for controlling the behavior of the language model. The temperature setting influences the randomness of the output, while the top P setting controls the diversity by limiting the token selection to a subset with the highest cumulative probability.
- Image Processing: Some models, like Claude 3 Haiku, support image processing. Ensure you connect a File Input to provide the required image input.
For more detailed information on configuring your AWS credentials and understanding the Bedrock service, refer to the AWS Bedrock Documentation.