AWS Textract
Automate document analysis with AWS Textract
What is the AWS Textract Node?
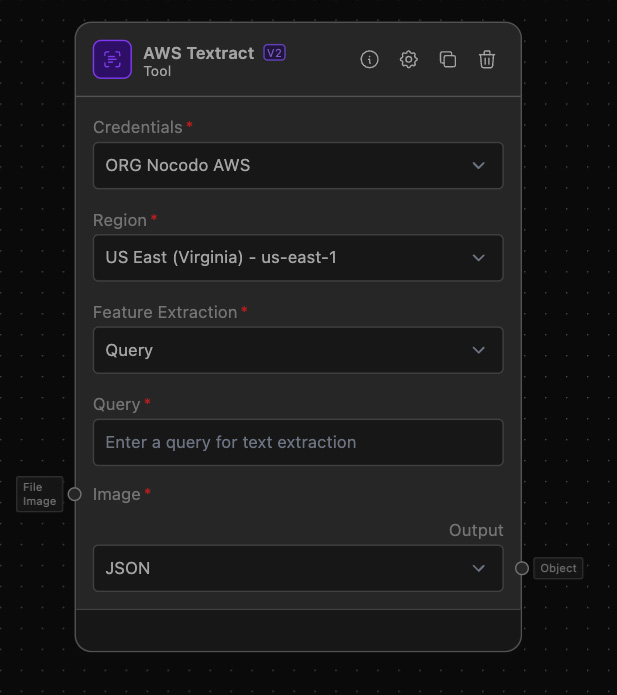
The AWS Textract Node enables automated extraction of text, forms, tables, and structured data from scanned documents using Amazon Textract. This service leverages machine learning to read documents as a human would, which is ideal for processing a wide array of document types without manual intervention. AWS Textract supports various feature modes like Forms, Layout, Queries, Signatures, and Tables, catering to diverse document analysis requirements.
How to use it?
To effectively utilize the AWS Textract node within your workflows, follow these steps:
-
Initial Setup:
- Drag the AWS Textract node into your workflow canvas.
-
Document Input:
- Provide a document image or file by connecting an output from a suitable node (e.g., File Reader node) to the
Imageinput anchor of the AWS Textract node. This node accepts images and PDF files as input, which it will process to extract data.
- Provide a document image or file by connecting an output from a suitable node (e.g., File Reader node) to the
-
Configure Extraction Features:
- Select the
Feature Extractionmode based on your document processing needs. Each mode optimizes the extraction for specific elements within the document:- Forms: Extracts data from forms such as entries in fields.
- Layout: Processes the general layout including headers, paragraphs, and footers.
- Queries: Uses natural language queries to extract specific information.
- Signatures: Identifies and extracts signatures.
- Tables: Recognizes and extracts tables effectively.
- If the
Queriesmode is selected, specify aQuerythat defines what information Textract should look for in the document.
- Select the
-
Output Configuration:
- Configure the output settings of the AWS Textract node to either receive extracted data as JSON text or as files. This allows flexibility depending on the subsequent use of the extracted data in your workflow.
Required AWS IAM Roles and Permissions
To ensure smooth operation, the AWS account must have appropriate permissions, for details how to create the required Secret Key see How to Generate and Use AWS Secret Keys:
- Amazon S3: Required to fetch documents (
s3:GetObject). - Amazon Textract: Necessary for document processing (
textract:*).
You can learn more about configuring AWS Textract and the necessary IAM permissions on the AWS Textract documentation page.
Example Taks: Extracting data from scanned forms for vector analysis
Objective: Develop a process to extract data from scanned forms and prepare it for vector analysis, ensuring accurate and efficient digitization and organization of the extracted information.
Step-by-Step Setup
- Prepare the Document:
- Use the File Reader node to retrieve a scanned form stored in AWS S3.
- Extract Data:
- Set the AWS Textract node to use the
Formsfeature mode to process the scanned document.
- Set the AWS Textract node to use the
- Store Data:
- Connect the output to a Vector Store Writer node to transfer the extracted data into a vector database for subsequent analysis or retrieval.