OpenAI Whisper
Effortlessly transcribe spoken audio into text using OpenAI Whisper.
What is OpenAI Whisper?
OpenAI Whisper is a powerful tool that transcribes spoken audio to text using OpenAI's Whisper model. This tool requires an audio file and an OpenAI API Key to function. Users can also adjust the model's style and temperature to refine the output. The transcription results can be provided in multiple formats including text, JSON, SRT, and VTT.
How to use it?
Using the OpenAI Whisper involves several steps, which are outlined below:
-
Set OpenAI API Key:
- Enter your OpenAI API Key. This is mandatory and is used to authenticate requests to OpenAI's API.
-
Set Model Temperature:
- Specify the model temperature. This parameter influences the creativity of the transcription. The default value is set to 0.
-
Upload Audio File:
- Provide the audio file you wish to transcribe. This is a required input.
-
Optional Prompt:
- Optionally, provide a prompt to guide the transcription process.
-
Select Output Format:
- Choose the desired output format for the transcription. Options include Text, JSON, SRT, VTT, and Verbose JSON. The default is set to Text.
Example of usage
OpenAI Whisper can be used to transcribe audio interviews into text for further analysis.
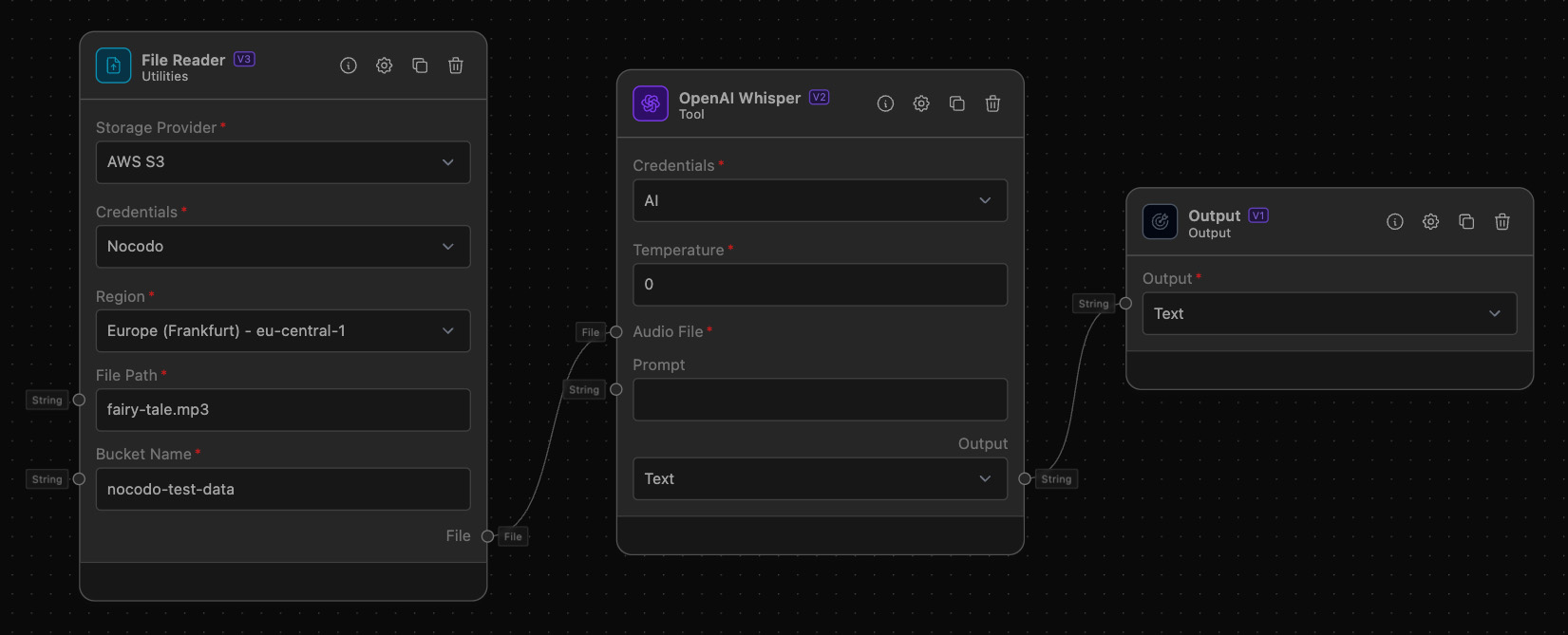
Example Task: Transcribe an Audio Interview
Objective: Convert an audio file of an interview into text for documentation and analysis.
Step-by-Step Setup
-
Configure OpenAI Whisper:
- Select the OpenAI Credentials
- Define the model temperature, for this example we use 1.
-
Upload the Audio File:
- Connect the audio file to the "Audio File Reader" input anchor.
-
Choose Output Format:
- Select the desired output format from the "Output" dropdown. For this example, choose "Text".
-
Connect to Output:
- Connect the "Transcription" output anchor to the Text Output, to display the transcribed text.
Additional Information
Ensure that your OpenAI API Key has permissions to access the Whisper transcription service. For best results, use clear audio recordings and, if possible, provide a guiding prompt to improve the accuracy and relevance of the transcriptions.
By following these steps, you can effectively use OpenAI Whisper to transcribe audio files into various text formats, enabling seamless integration into your workflows and applications.